
LLMO構造化データという言葉を目にしても、LLMOの意味や構造化データとの関係がすぐにはピンと来ない方も多いでしょう。SEOとは違う新しい最適化の概念として注目されていますが、具体的に何をどう整備すればよいのか分かりにくいのが現状です。
LLMOとは「Large Language Model Optimization(大規模言語モデル最適化)」の略で、ChatGPTなどのAIに自社情報を正しく理解・引用してもらうための施策を指します。そのLLMO対策において、構造化データは機械が情報を読み取りやすくする重要な役割を担っています。
本記事では、LLMOの基本概念から構造化データがなぜ重要なのか、そして具体的にどう活用すべきかを初学者にも分かりやすく解説します。この記事を読めば、LLMO対策の全体像を理解し、自社サイトで何から始めるべきかを判断できる状態になります。
LLMO(Large Language Model Optimization)とは
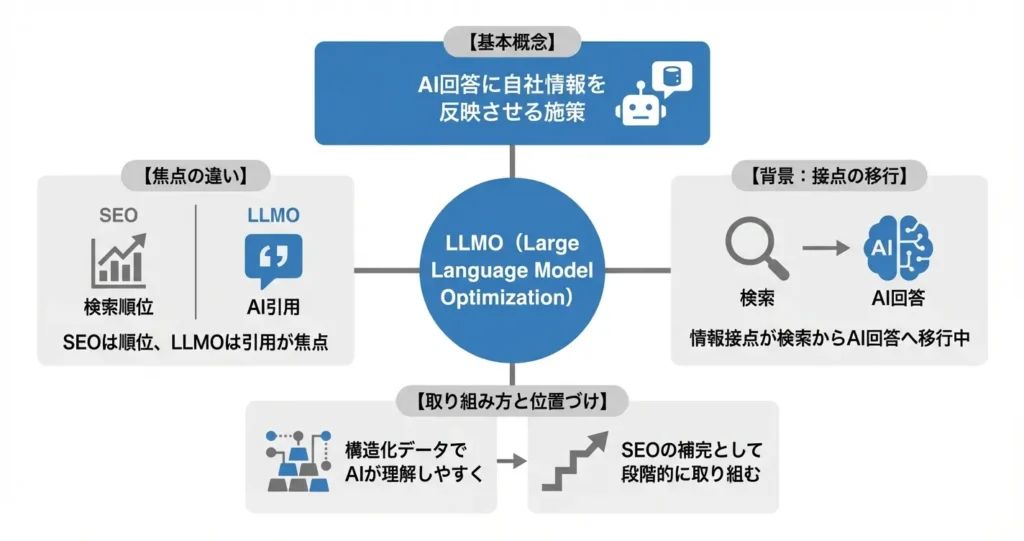
LLMOとは、ChatGPTやGeminiなどの大規模言語モデルが生成する回答に、自社の情報を適切に反映させるための最適化施策を指します。
検索エンジンを対象としたSEOに対し、LLMOはAIによる回答生成を対象とする点で新しい概念です。
生成AIの普及に伴い、情報収集の起点が検索結果からAIの回答へと移行しつつある状況を背景に、企業やメディアにとって無視できない領域として注目されています。
LLMOの定義と登場背景
LLMOは、Large Language Model Optimizationの略称であり、大規模言語モデルによる情報生成の過程で、自社コンテンツが参照されやすくする取り組み全般を意味します。
ここでいう「LLMの最適化」とは、モデルそのものを改良するのではなく、モデルが情報を取得・理解する際に自社コンテンツを認識しやすくする施策を指します。
具体的には、構造化データの実装、明確な情報構造の整備、引用元として適切なコンテンツ形式の採用などが含まれます。
従来の検索エンジン最適化が検索結果ページでの表示順位を重視していたのに対し、LLMOではAIが回答を生成する際に引用・参照されるかどうかが焦点となります。
この概念が登場した背景には、ChatGPTをはじめとする生成AIの急速な普及があります。
利用者がWebブラウザで検索する前にAIに質問を投げかける行動が増え、情報との最初の接点がAIの回答文に移りつつある現状があります。
こうした変化に伴い、従来のSEO施策だけでは情報の可視性を確保できない状況が生まれ、LLMOという新たな視点が必要とされるようになりました。
SEOとLLMOの違い
SEOとLLMOは、いずれも自社情報を適切に届けるための施策ですが、最適化の対象と評価の仕組みが根本的に異なります。
SEOは検索エンジンのアルゴリズムを対象とし、クローラビリティやページ評価といった要素が重視されます。
一方、LLMOは言語モデルによる情報の理解と生成を対象とし、構造化データや文脈の明確さが重要な役割を果たします。
構造化データは、AIが「この情報を引用しやすい」と判断する材料になります
構造化データがLLMOで重視される理由は、大規模言語モデルが情報を取得・解釈する際に、明示的にマークアップされたデータを優先的に参照する傾向があるためです。
たとえばSchema.orgの語彙を用いた構造化データは、企業名・商品情報・価格・評価といった要素を機械可読な形で提供します。
そのため、AIが回答を生成する際の情報源として採用されやすくなります。
SEOにおいても構造化データは有効ですが、LLMOではより直接的に回答生成の精度と引用可能性に影響します。
また、成果の現れ方にも違いがあります。
SEOでは検索順位やクリック率といった指標で効果を測定できますが、LLMOではAIによる引用や参照の有無、回答文への反映度合いといった、より定性的な評価が中心となります。
このため、施策の設計や効果検証においても、従来とは異なるアプローチが求められます。
LLMOが重要視される理由
LLMOが重要視される最大の理由は、情報接触の起点がAIによる回答へと移行しつつあるためです。
検索エンジン経由でのサイト訪問を前提とした従来の導線設計では、AIが直接回答を生成する場面において自社情報が届かない可能性があります。
特に、ブランド認知や初期検討段階において、AIの回答文に含まれるかどうかが情報の到達率に直結する状況が生まれています。
生成AIの利用は拡大傾向にあるものの、検索エンジン経由の情報収集も依然として主要な導線であり、業種や情報の性質によってAIと検索エンジンの使い分けが進んでいる段階にあります。
そのため、今すぐ全面的な対応が必要というよりも、既存のSEO施策と並行して段階的に取り組むことが現実的な選択肢となります。
加えて、大規模言語モデルは学習データや外部情報源を基に回答を生成するため、情報の構造化や引用されやすい形式での公開が、可視性を左右する要因となります。
SEOで評価されるコンテンツであっても、AIが理解・参照しやすい形式になっていなければ、回答に反映されない可能性があるため、両面からの最適化が求められるようになっています。
ここまででLLMOの基本的な概念と背景、そして構造化データとの関連性を整理しました。次のセクションでは、LLMOにおいて構造化データが具体的にどのような役割を果たすのかについて、さらに詳しく見ていきます。
LLMOにおける構造化データの役割
LLMO(Large Language Model Optimization) とは、大規模言語モデル(LLM)を活用したAIサービスにおいて、自社のコンテンツが適切に参照・引用されるよう最適化する取り組みを指します。
ChatGPTやMicrosoft Copilot、Google GeminiといったAIチャットサービスが回答を生成する際、より正確に情報を理解し、引用元として選ばれやすくするための施策全般 がこれに含まれます。
LLMOの文脈で構造化データが重視される理由は、LLMが情報を処理する仕組みと密接に関わっています。
構造化データを適切に実装することで、LLMによる情報の理解精度が高まり、結果としてAIサービス上での表示や回答品質に影響を与える可能性があります。
このセクションでは、LLMの情報処理の特性を踏まえながら、構造化データがLLMOにおいて果たす役割を整理します。
LLMが情報を理解する仕組み
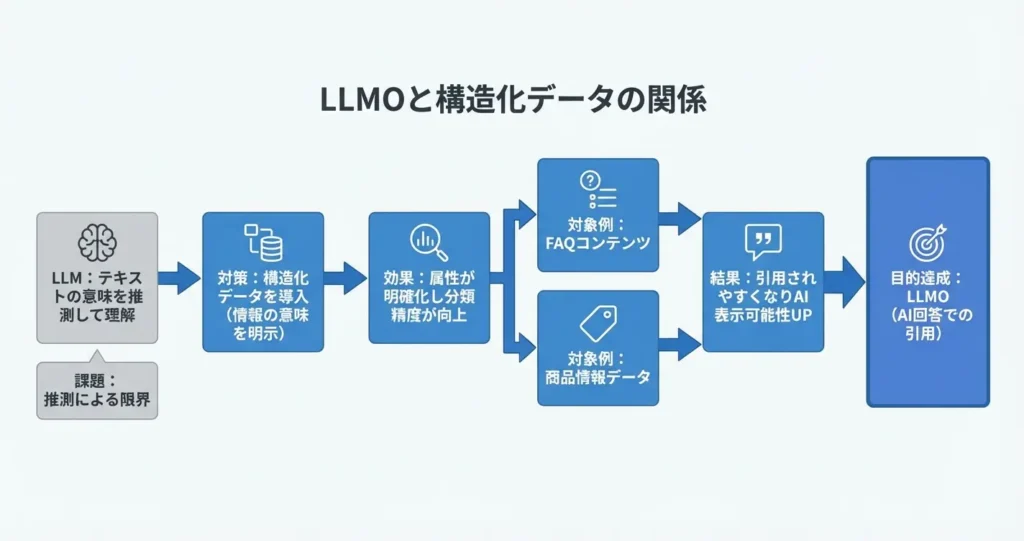
LLMは、Webページ上のテキストを読み取り、その内容を文脈として解釈することで情報を理解します。
HTMLのタグや文章の構造、単語の関係性などを手がかりに、そのページが何について述べているのか、どのような情報を提供しているのかを推測する仕組みです。
ただし、LLMは人間と異なり、視覚的なレイアウトやデザインを認識するわけではありません。
あくまでマークアップされたテキスト情報を順序立てて解釈するため、情報の意味や関係性が明示されているほど、正確な理解が可能になります。
構造化データは、この「意味の明示」を実現する手段の一つとして機能します。
構造化データがLLMに与える影響
構造化データは、ページ内の情報に対して明確なラベルと関係性を付与する役割を持ちます。
たとえば、ある情報が商品名なのか、価格なのか、評価なのかといった属性を、機械が解釈しやすい形式で記述することで、LLMはその情報をより正確に分類し、文脈に沿った処理を行いやすくなります。
構造化データがあることで、LLMは「この部分は価格」「ここは評価」と明確に判断できるようになります
LLMが情報を取得する際、構造化データが存在することで、通常のテキスト解析に比べて情報の意味を判別しやすくなります。
これにより、LLMが回答を生成する際の判断材料として、より明確で信頼性の高い情報源を利用できる環境が整います。
構造化データはLLMOにおける必須要件ではありませんが、情報の意味を明示的に伝える有力な手段として位置づけられています。
特にFAQ・商品情報・イベント情報など定型的な情報を扱うページでは導入効果が期待されています。
AIサービスでの表示への関連性
多くのAIサービスやLLMベースの検索機能では、回答生成時に複数の情報源を参照し、適切な情報を抽出して提示します。
この過程において、構造化データが実装されているページは、情報の抽出や引用がしやすいという特性を持ちます。
たとえば、FAQページにFAQPageスキーマが実装されている場合、LLMは質問と回答のペアを明確に識別できるため、ユーザーの質問に対して該当する回答を正確に引用しやすくなります。
同様に、商品情報やレビュー、イベント情報なども、構造化データによって意味が明確化されていれば、AIサービス上での引用や表示の対象として選ばれる可能性が高まります。
ここまでで、LLMOにおいて構造化データがどのような役割を果たすかが整理できました。
次に気になるのは、具体的にどのような種類の構造化データが存在し、それぞれがどのような情報を表現できるのかという点です。
次のセクションでは、LLMOの観点から注目される主要な構造化データの種類について解説します。
LLMO対策で活用される構造化データの種類
LLMO対策として活用される構造化データには、いくつかの代表的な形式と語彙が存在します。それぞれの役割や用途を理解することで、自社のコンテンツに適した構造化データを選択できるようになります。
ここでは、標準的な語彙の体系、実装形式、そしてLLMOにおいて特に重視されるデータタイプを順に整理します。
なお、構造化データがLLMOで重要な理由は、LLMが自然言語を理解できるとはいえ、HTMLで表示されたテキストからは情報の種類や関係性を推測するしかないためです。
構造化データがあれば「これは記事タイトルである」「これは著者名である」「この日付は公開日である」といった明示的な情報をLLMに提供でき、LLMが回答を生成する際の情報抽出の精度が向上します。
構造化データがない場合、LLMはページ全体の文脈から該当情報を探す必要があり、誤った情報を引用したり、重要な情報を見落としたりする可能性が高まります。
Schema.orgの主要な語彙
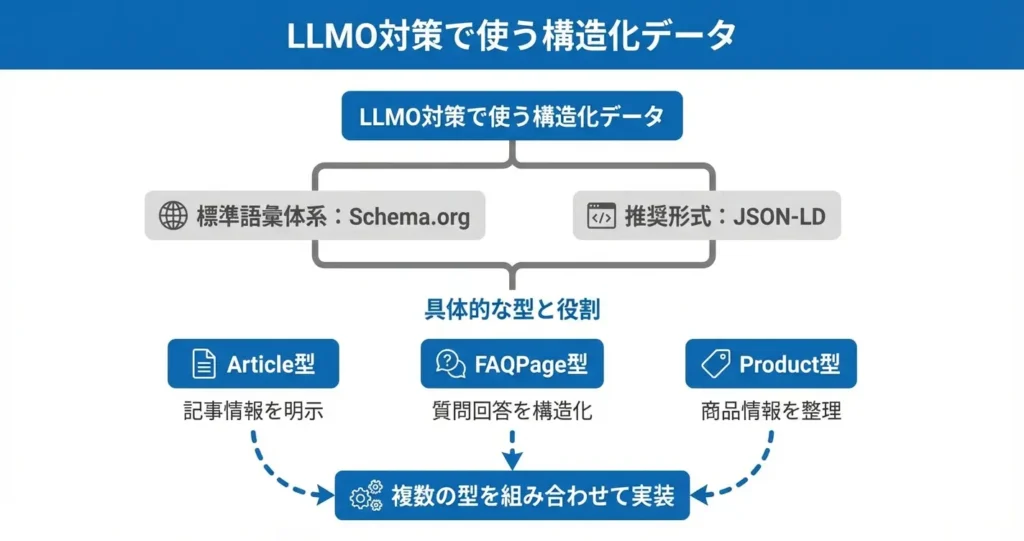
Schema.orgは、Google、Microsoft、Yahoo、Yandexなどの検索エンジン企業が共同で策定した構造化データの語彙体系であり、Webページ上の情報を機械可読な形式で記述するための標準として広く採用されています。
この語彙体系は階層構造を持ち、Thing(事物)を最上位として、CreativeWork(創作物)、Organization(組織)、Person(人物)、Product(製品)、Event(イベント)といった主要なカテゴリに分類されています。
各カテゴリにはさらに詳細なプロパティが定義されており、たとえばArticle型であれば見出し、著者、公開日、本文といった属性を構造化して記述できます。
- headline(記事の見出し)
- author(著者名とその所属組織)
- datePublished(公開日時)
- dateModified(最終更新日時)
- image(記事に関連する画像のURL)
- articleBody(本文の要約または全文)
これによりLLMは「この記事は誰が、いつ書いたもので、何について述べているのか」を明確に把握できます。
LLMがコンテンツを解析する際、この標準化された語彙に基づいて情報を抽出・整理するため、Schema.orgに準拠した記述を行うことがLLMO対策の基本となります。
JSON-LD形式の基本
構造化データの実装形式にはいくつかの選択肢がありますが、現在最も推奨されているのがJSON-LD形式です。
JSON-LDはJavaScript Object Notation for Linked Dataの略称であり、HTMLのhead要素またはbody要素内にscriptタグとして埋め込む形で記述します。
この形式はHTMLの構造と独立しているため、既存のページに影響を与えずに追加でき、保守性や可読性が高いという利点があります。
また、複数の構造化データを一つのページに共存させることも容易であり、ArticleとBreadcrumbListを併用するといった実装が一般的に行われています。
JSON-LD形式なら、HTMLのマークアップに手を加えずに構造化データだけを追加できるので、既存サイトにも導入しやすいですね
LLMがWebページの情報を取得して回答を生成する際も、JSON-LD形式であれば明確に構造化データとして認識しやすく、HTMLのマークアップと混在するMicrodataやRDFa形式に比べて解釈の曖昧さが生じにくいとされています。
LLMOで特に重視される構造化データ
LLMO対策において優先的に実装が検討される構造化データには、コンテンツの性質に応じていくつかの代表的な型が存在します。
Article型は記事コンテンツの基本情報を示すもので、見出し、著者、公開日、更新日、本文の要約といった属性を記述することでLLMに記事の概要を明確に伝えます。
FAQPage型は質問と回答のペアを構造化するもので、ユーザーの疑問に対する直接的な回答をLLMが抽出しやすくなるため、ChatGPTやMicrosoft CopilotなどのAIチャットサービスが回答を生成する際に引用される可能性が高まります。
Product型はECサイトや製品紹介ページで使用され、製品名、価格、在庫状況、評価といった商品情報を構造化することで、LLMが製品比較や推薦を行う際の情報源として活用されます。
BreadcrumbList型はサイト内の階層構造を示し、コンテキストの理解を助けます。Organization型やWebSite型は、サイト全体の運営主体や検索機能といったメタ情報を提供します。
構造化データの種類と形式が理解できたところで、次に気になるのは実際にどのように実装すればよいかという点です。
次のセクションでは、LLMO対策として構造化データを実装する際の具体的な手順と注意点を解説します。
構造化データとは?基本をおさらい
LLMO対策における構造化データの役割を理解するには、まず構造化データそのものの概念を整理する必要があります。
このセクションでは、構造化データの定義と非構造化データとの違い、そしてウェブサイトでの実装方法を確認します。基礎を押さえることで、LLMOにおいて構造化データがどのように機能するかが明確になります。
なお、LLMOとはLarge Language Model Optimization(大規模言語モデル最適化)の略で、ChatGPTやMicrosoft Copilot、Google Geminiといった生成AIが情報を引用・参照する際に、自社サイトのコンテンツが選ばれやすくする取り組みを指します。
従来のSEOが検索結果ページでの表示順位を目指すのに対し、LLMOはAIの回答内で情報源として引用されることを目指す点が特徴です。この文脈において、構造化データは機械が情報を正確に理解し抽出するための重要な手がかりとなります。
構造化データの定義
構造化データとは、一定の規則に基づいて整理され、機械が解釈しやすい形式で記述されたデータのことを指します。
ウェブサイトにおいては、HTMLで表示されているコンテンツの意味や関係性を、検索エンジンやAIが正確に理解できるよう、あらかじめ定められた語彙とフォーマットでマークアップする手法として用いられます。
たとえば、記事の公開日、著者名、商品の価格、レビューの評価といった情報を、人間が読むテキストとは別に、機械が読み取れる形式で付与することで、より正確な情報伝達が可能になります。
LLMOの文脈では、この機械による正確な理解が特に重要です。大規模言語モデルは膨大な情報の中から回答に必要な要素を抽出する際、構造化データがあることで情報の信頼性や関連性を判断しやすくなり、結果として引用元として選ばれる可能性が高まると考えられています。
構造化データと非構造化データの違い
構造化データと非構造化データは、情報の整理方法と機械による処理のしやすさという点で対照的です。
構造化データは、あらかじめ定義されたスキーマに従って記述されるため、データベースのように検索や抽出が容易である一方、非構造化データは自然言語の文章や画像、動画など、決まった形式を持たない情報を指します。
ウェブサイトにおいては、ページ本文の文章は非構造化データであり、それに付与するスキーママークアップが構造化データという関係になります。
非構造化データは人間向けの文章、構造化データは機械向けの補足情報と考えると分かりやすいですね
大規模言語モデルは非構造化データの理解が可能ですが、構造化データが併存することで情報の特定要素を確実に把握できるため、AIが回答生成時に参照する情報源としての信頼性判断がより正確に行われます。
これがLLMOにおいて構造化データが重視される理由です。
ウェブにおける構造化データの実装方法
ウェブサイトに構造化データを実装する方法として、現在主流となっているのはJSON-LD、Microdata、RDFaの3つの形式です。
このうちGoogleが推奨し、最も広く採用されているのはJSON-LD形式であり、HTMLのheadセクションやbodyタグの末尾にscriptタグとして記述することで、ページ本文のマークアップに影響を与えずに構造化データを追加できます。
記述する内容はSchema.orgという語彙体系に基づいており、記事であればArticle、商品であればProductといったタイプを指定し、その配下に必要なプロパティを定義していく構造になります。
実装後はGoogleのRich Results Testなどのツールで検証し、正しく認識されるか確認することが推奨されます。
構造化データの基本を理解したところで、次のセクションでは、LLMOにおいて構造化データがどのような具体的な効果をもたらすのか、そしてどのタイプの構造化データが特に重要視されるのかを掘り下げていきます。
LLMOと構造化データの関係性まとめ
LLMO(Large Language Model Optimization)とは、ChatGPTやMicrosoft Copilot、Google Geminiなどの大規模言語モデルが生成する回答の中で、自社の情報が引用・参照されやすくなるよう最適化する取り組みを指します。
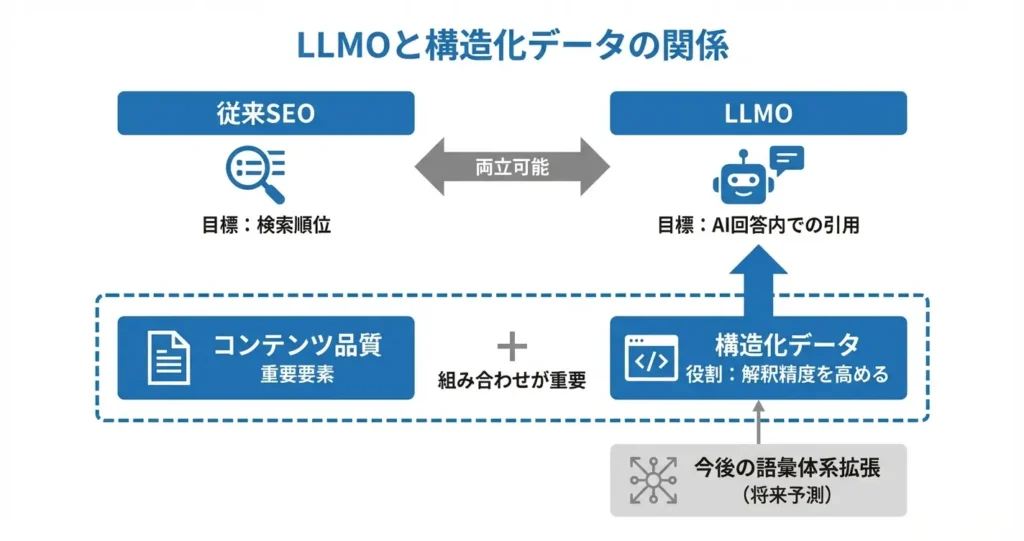
従来の検索エンジン最適化(SEO)が検索結果ページでの表示順位を目指すのに対し、LLMOはAIが生成する回答文の中で情報源として提示されることを目指す点が特徴です。
LLMOと構造化データは、LLMが情報を正確に解釈し引用するための基盤として密接に結びついています。
ここではこれまでの内容を踏まえ、両者の関係性を全体像として整理し、従来のSEOとの違いや今後の展望を確認します。この整理によって、LLMO対策における構造化データの位置づけが明確になります。
LLMOにおける構造化データの位置づけ
構造化データとは、Schema.orgなどの語彙を用いてWebページ上の情報に意味付けを行い、機械が理解しやすい形式で記述する技術です。
LLMOにおいては、LLMが情報を正確に理解し回答に引用するための入力情報の明確さを高める役割を担います。
LLMは自然言語処理によってWebページの内容を読み取りますが、構造化データによって情報の意味や関係性が明示されていると、解釈の精度が向上し、引用対象として選ばれやすくなることが想定されます。
従来のSEOにおいても構造化データは検索エンジンへの情報伝達手段として活用されてきました。しかしLLMOにおいては、情報の解釈可能性を高める基盤として、より本質的な役割を果たします。
構造化データはLLMが情報を正しく読み取るための補助的な役割として位置づけられていますが、コンテンツ品質が前提となる点は理解しておく必要があります。
従来のSEO対策との比較
従来のSEOでは、検索エンジンのクローラーに情報を正確に伝え、検索結果ページでの表示を最適化することが主な目的でした。
構造化データはリッチリザルトの表示やナレッジグラフへの反映を目的に実装されることが多く、視覚的な訴求力やクリック率の向上が重視されてきました。
一方LLMOにおいては、LLMが生成する回答文の中で引用され、ユーザーに情報源として提示されることが目標となります。
このため、情報の正確性や文脈の明確さがより重視され、構造化データも検索結果での見栄えよりも、LLMによる解釈精度の向上に寄与する役割が期待されます。
- 目標地点:SEOは検索結果ページでの上位表示、LLMOはAI回答内での引用
- 構造化データの役割:SEOでは表示の最適化、LLMOでは解釈精度の向上
- 評価指標:SEOでは順位やクリック率、LLMOでは引用頻度や参照元としての提示
ただし両者は対立する概念ではなく、構造化データの実装によって従来のSEOとLLMOの両方に効果が期待できる場合も多くあります。
今後の展望
LLMを活用した情報探索が普及するにつれ、構造化データの役割はさらに重要性を増すと考えられます。
現時点ではLLMOの評価手法や最適化手法が研究・検証段階にあり、どの施策がどの程度効果を持つかは明確に確立されていません。
しかし、情報の信頼性や引用可能性を高めるための基礎的な手法として、構造化データの実装は今後広く推奨される方向にあると見られています。
また、Schema.orgをはじめとする構造化データの語彙体系も、LLMによる情報解釈を前提とした拡張や改善が進む可能性があります。
企業や組織にとっては、従来のSEO対策の延長線上でLLMOに対応できる環境を整えることが、今後の情報発信戦略において重要な要素となるでしょう。
ここまでLLMOと構造化データの基本的な関係性を整理してきましたが、次は実践的な実装・運用のポイントを確認しましょう
LLMO構造化データ対策を始める前に知っておくべきこと

LLMO(Large Language Model Optimization)とは、ChatGPTやMicrosoft Copilot、Googleの生成AI検索など、大規模言語モデル(LLM)を活用した情報提供サービスにおいて、自社の情報が適切に引用・参照されるよう最適化する取り組みを指します。
従来のSEOが検索結果ページでのランキング向上を目的とするのに対し、LLMOはAIによる回答文の中で自社情報が正確に引用されることを目指す点が特徴です。
Web検索との連携機能を持つAIサービスでは、ウェブ上の情報をリアルタイムで収集して回答を生成することがあります。その際、構造化データ(Schema.orgなどの形式で記述された機械可読な情報)があると、LLMは情報の意味や関係性を正確に理解しやすくなります。
これは、LLMが自然言語処理を行う際に、明示的に整理された情報の方が曖昧さを排除でき、引用元としての信頼性を判断しやすいためです。このような背景から、LLMが普及する現在の検索環境において、構造化データの重要性が再評価されています。
LLMO対策は、すべてのサイトで同じ優先度で取り組むべき施策ではありません。自社サイトの現状や目的に応じて、取り組む範囲や順序を適切に判断する必要があります。
また、既存のSEO施策との関係性を理解し、誤った実装を避けることも重要です。このセクションでは、実際に対策を始める前に押さえておくべき判断軸と注意点を整理します。
自社サイトでの優先度の見極め方
- サイトが扱う情報の性質(事実情報か感性的表現か)
- ターゲットユーザーの検索行動(即答を求めるか詳細な比較か)
- ビジネス成果への影響度(問い合わせや購買につながるか)
LLMO構造化データ対策の優先度は、サイトの種類とユーザーの情報探索行動によって大きく変わります。
LLMによる回答が求められやすい領域、つまりユーザーが「すぐに答えを知りたい」「複数の情報源を比較したい」という場面では早期の対応が有効です。一方、そうでない場合は従来のSEO施策を優先すべきです。
優先度を判断する際は、自社サイトが扱う情報の性質と、ターゲットユーザーがどのような検索行動を取るかを基準にすることが推奨されます。
対策の優先度が高いサイトとしては、よくある質問に対する明確な答えを提供するFAQサイトや製品仕様、営業時間や価格情報など事実情報を扱う企業サイト、専門用語の定義や手順を解説するナレッジサイトが挙げられます。
これらは構造化データによる情報整理が回答精度の向上に直結しやすい領域です。たとえば「レストランの営業時間」や「製品の保証期間」といった情報は、LLMが直接回答する際に引用されやすく、構造化データがあることで正確性が高まります。
一方で、ブランドストーリーや感性的な表現が重視されるコーポレートサイト、個別性の高い相談や提案が前提となるBtoBサービスサイト、リアルタイムの在庫状況や最新ニュースなど更新頻度の高い情報を扱うサイトでは、構造化データよりも他の施策を優先すべき場合があります。
これらの領域では、LLMによる一般的な回答よりも、直接サイトを訪問しての確認や問い合わせが重視される傾向があるためです。
既存のSEO施策との両立
LLMO対策は、従来のSEO施策を置き換えるものではなく、その延長線上に位置づけられる施策です。
検索エンジンのクローラーは主にリンク構造とキーワードを重視してページを評価しますが、LLMのデータ収集では情報の意味的な関係性や文脈の整合性をより重視します。ただし、いずれも構造化された情報とコンテンツの質を評価する点では共通しています。
そのため、基本的なSEO施策が不十分な状態でLLMO対策だけを行っても、期待する効果は得られません。
まずはSEOの基礎を固めてから、構造化データを追加していくのが確実です
優先すべき順序としては、まず検索エンジンに正しくインデックスされる技術的基盤を整え、ユーザーにとって価値のあるコンテンツを提供することが第一です。その上で、既存コンテンツに構造化データを追加し、LLMが理解しやすい形式に整えていくのが現実的なアプローチといえます。
既存のSchema.orgマークアップを実装している場合は、それがLLMO対策の基礎としても機能します。ただし、検索結果のリッチリザルト表示を目的とした実装と、LLMへの情報提供を目的とした実装では、記述すべき情報の範囲が異なる場合があるため、目的に応じた見直しが必要になることもあります。
避けるべき誤った実装
構造化データの実装において最も避けるべきは、実際のページ内容と構造化データの内容が一致しないケースです。
LLMは構造化データとページ本文の両方を参照するため、情報に矛盾があるとLLM側での信頼性評価が下がり、回答への引用対象から外れる可能性があります。また、検索エンジンからはスパムとみなされるリスクもあるため、必ずページ内に記載されている情報のみを構造化データとして記述する必要があります。
過剰な実装も注意が必要です。すべてのページに無理に構造化データを追加しようとすると、メンテナンスコストが増大し、更新漏れによる情報の陳腐化を招きます。
対策を始める際は、月間アクセス数が多いページや問い合わせにつながりやすいページなど、ビジネス成果への影響が大きいページから段階的に実装し、運用体制を整えながら範囲を広げていくことが推奨されます。
また、LLMへの最適化だけを意識しすぎて、人間が読みにくいコンテンツにならないよう注意が必要です。構造化データはあくまで補助的な情報であり、ページの主要なコンテンツは人間のユーザーにとって読みやすく価値のある内容であることが前提です。
この原則を守ることで、検索エンジンとLLMの両方から適切に評価される持続可能な施策となります。
ここまでLLMO構造化データの概念から実装の注意点まで整理してきました。自社サイトにおける優先度と現状を照らし合わせながら、段階的に取り組むことで、LLMを活用した情報提供サービスが普及する環境における情報発信の最適化を進めることができます。
よくある質問
LLMOやSEOの基本概念、構造化データの扱いなど、施策を進める上で多くの方が疑問に感じるポイントをまとめました。
ここでは、実務で押さえておくべき用語の意味や対策の方向性について、分かりやすく解説します。
それぞれの質問を通じて、判断に必要な基礎知識を整理していきましょう。
LLMOとは何ですか?
LLMOは「Large Language Model Optimization」の略称で、大規模言語モデルに対する最適化を意味します。
ChatGPTやGoogle GeminiといったAIサービスが回答を生成する際に、自社の情報を適切に理解し、正確に引用してもらうための施策全般を指します。
従来の検索エンジン最適化とは異なり、AI対話型サービスでの情報露出を高めることを目的としています。
LLMO対策でやることは?
構造化データの実装は、ページ内の情報をLLMが機械的に読み取りやすくするための土台となります。
コンテンツ面では、見出しや段落構造を明確にし、質問と回答の対応関係をわかりやすく整理することが重要です。
加えて、信頼性シグナルの強化として、著者情報や引用元の明示、専門性を示す記述を適切に配置することで、LLMからの評価向上が期待できます。
構造化データと非構造化データはどちらが多い?
Web上に存在するデータの大半は、非構造化データです。
通常のテキストや画像、動画、音声など形式が自由なコンテンツが圧倒的多数を占めています。
一方で、表形式やタグ付けされた構造化データは全体の一部に過ぎません。
ただし現在はLLMがコンテンツを正確に理解するために、構造化データの活用が重要視されるようになっています。
検索エンジンやAIが情報を適切に解釈できるよう、構造化マークアップの導入が推奨される場面が増えています。
SEOでやってはいけないことは何ですか?
誤った構造化データの実装や、スパム的なマークアップの使用は避ける必要があります。
特に実際のコンテンツと乖離した情報を構造化データに記述すると、AIによる誤認識や評価低下につながる可能性があります。
また、過度なキーワードの詰め込みや、ユーザーの意図と無関係な情報の羅列も、LLMO文脈では不利に働くことがあります。
コンテンツの質と構造化データの整合性を保つことが重要です。
構造化データの具体例は?
代表的なものとして、記事情報(Article)はブログ記事やニュースに使われ、見出しや公開日を構造化します。
FAQは質問と回答のペアを明示し、検索結果に直接表示されることがあります。
商品情報(Product)では価格や在庫状況、レビュー評価などを記述でき、企業情報(Organization)では会社名や所在地、ロゴなどを構造化できます。
いずれもSchema.orgで定義された語彙を使い、検索エンジンに内容を正確に伝える役割を持ちます。








コメント